Pipeline Hub
Unified Data Operations Dashboard
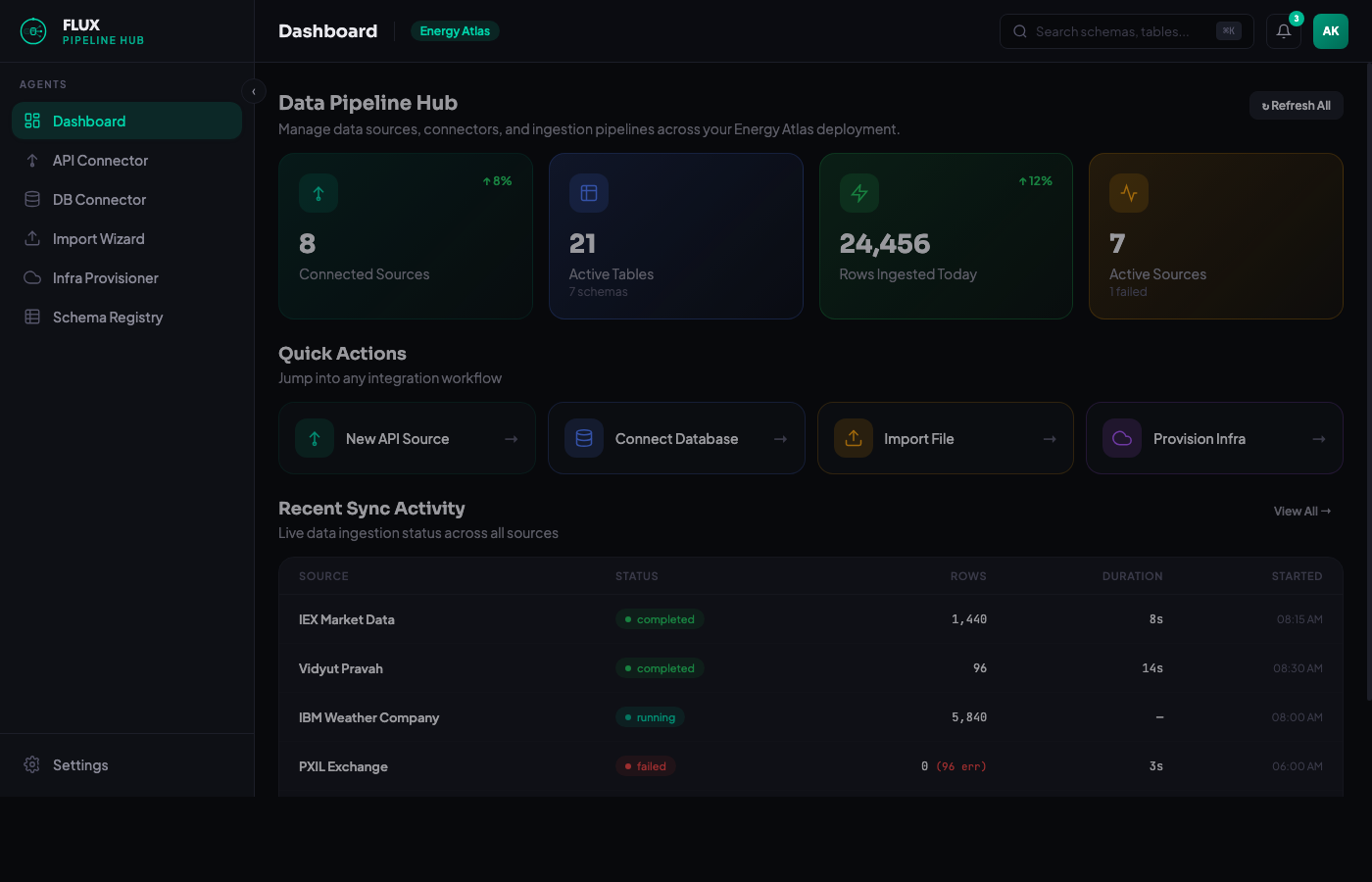
A single pane of glass for all data pipeline operations. Monitor connected sources, active tables, rows ingested, sync status, and failure alerts — with quick actions to jump into any integration workflow instantly.
- hub 8 connected sources with 21 active tables across 7 schemas
- bolt 24,456 rows ingested today with real-time sync activity feed
- speed Quick Actions: New API Source, Connect Database, Import File, Provision Infra
- notifications_active Live sync status: completed, running, failed — with instant retry